
AESIP: Arch-aware ASIP-ISA Co-Design via Program Synthesis
Duration: Jul. 2025 – Nov. 2025 Advisor: Prof. Nathaniel Bleier at University of Michigan
Overview
A program may use only a small subset of instructions from an ISA, making it possible to design Application Specific Integrated Processors (ASIPs) by removing unused hardware without affecting correctness of programs. AESIP is a microarchitecture-aware ASIP-ISA co-design framework that leverages hardware-aware program rewriting to automatically generate optimized ASIP-program pairs.
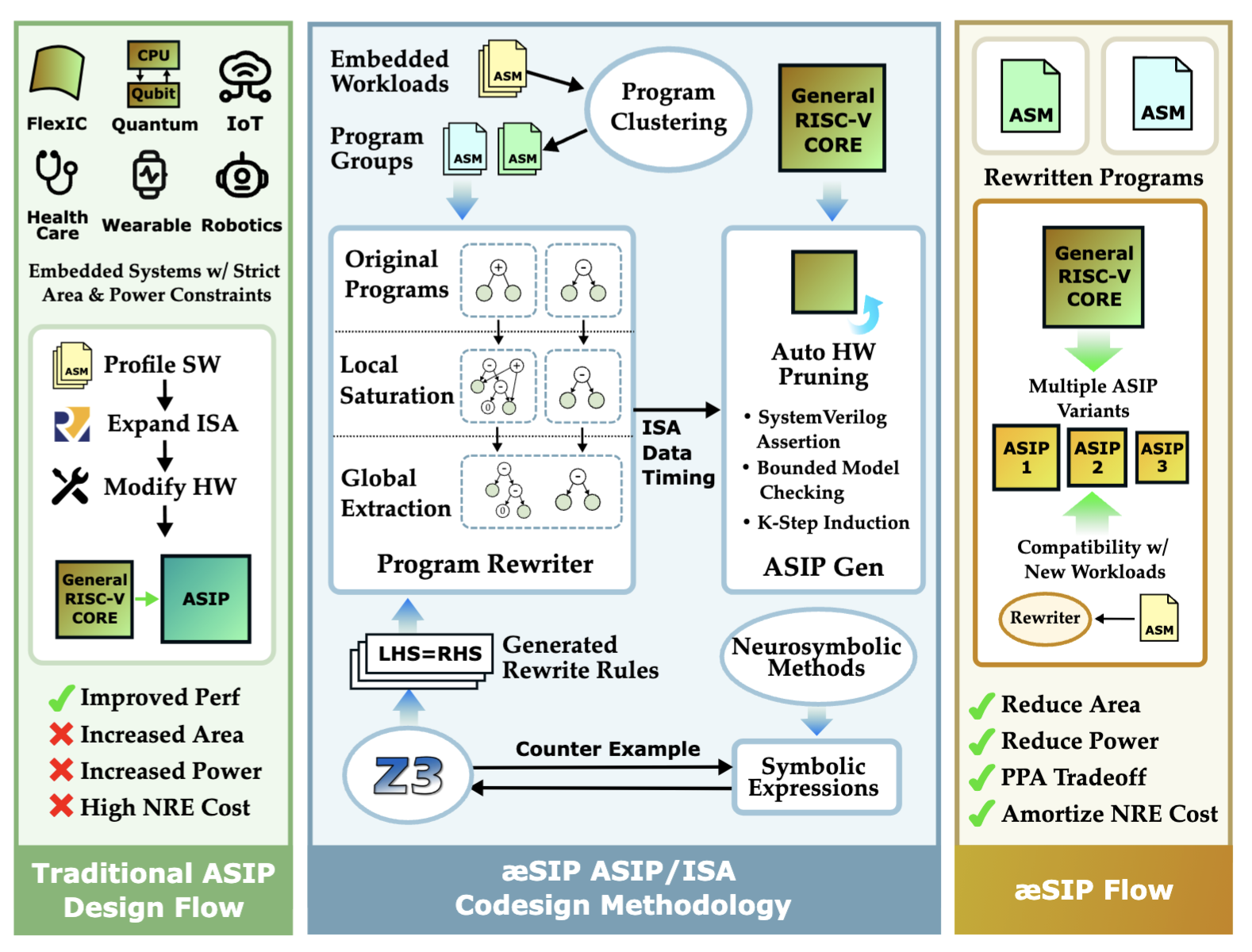
AESIP Hardware-Software Co-Design Framework
Motivation
With the end of Dennard scaling, ASIPs have emerged as a promising solution for power and area constrained applications including implantables, IoT devices, and printed electronics. However, existing approaches predominantly optimize hardware through software profiling, potentially overlooking optimization opportunities through software rewriting.
Key Contributions
- Program Synthesis Framework: Built a neuro-symbolic approach to automatically discover correctness-preserving rewrites that maximize hardware removal opportunities
- E-graph Based Exploration: Leveraged e-graph data structures to explore semantically equivalent software implementations through rewriting rules derived from program synthesis
- Scalable Architecture: Developed a divide-and-conquer approach with local saturation at basic-block granularity followed by ILP-based global extraction at whole-program scope
- Don’t Care-Based Optimizer: Created an automatic ASIP design generator for each equivalent program variant, enabling agile design space exploration
- Workload Clustering: Implemented clustering algorithm grouping applications with similar rewrite/ISA characteristics, with constraint-based sharing to limit ASIP variants
Results
Experimental evaluation on MiBench and Embench benchmark suites demonstrates:
- Up to 29.7% area reduction compared to state-of-the-art ASIP generators
- 8.3% power savings over baseline approaches
- Using only 4 shared ASIPs, achieves 14.17% area reduction with just 0.23% latency overhead
- Full per-application specialization achieves 19.11% area reduction at the same latency target
Significance
To our knowledge, this represents the first systematic hardware-software co-design framework for agile ASIP development that exploits generalization opportunities across diverse workloads without compromising specialization.